Clive, one of our lead Solution Architects with a lifetime of delivering IBM FileNet solutions, continues his Journey to the Cloud – this time recalling his experience of deploying a demo of Cloud Pak for Business Automation and a retrospective look at what it was like installing Enterprise deployments of CP4BA for the first time. To catch up on his previous blogs, here are part 1 and part 2.
Demo and Enterprise Deployments of Cloud Pak for Business Automation
The Installation
The first part of the installation was to install the operators from what’s known as the Operator Hub. When you go into Open Shift, there’s a catalogue of different applications that you can deploy. There are databases and tools for doing deployments and managing deployments automatically. IBM has created catalogue items for all of their Cloud Paks, including for Business Automation
When you install the Operator, it lays down all of the foundations for deploying an instance of Business Automation Workflow (BAW) or the Cloud Pak. Then, you’ve got a choice of either using a Graphical User Interface (GUI) or using YAML configuration files and tell it what type of deployment you want to do.
Demo deployments with automatic configuration
I started by saying I want to put in Business Automation Workflow, and I then selected the component parts. I began with a simple Content build, which would need the Content Platform Engine – what used to be the P8 Content Engine – and Navigator to access it so you can just add and retrieve documents. It then went away and automatically worked out the pre-req software and that includes the database. It being IBM, the default database that’s put down as part of a demo build is DB2 and a Lightweight Directory service – Open LDAP.
It automatically laid down all of the pre-reqs (the database and the LDAP), and it configured those for the selected components. You can choose anything from a simple Content build all the way up to an all-singing, all-dancing build using ADP (Automation Document Processing), Workflow, ODM (Operational Decision Manager), Rules and BAI (Business Automation Insights).
Mixed Success
I was successful in deploying a demo on the office servers in this way. However, on my servers at home, I tried several times to get it built and selecting everything seemed to need a lot of memory and CPUs. It’s resource-heavy.
Next, I had a go at deploying a demo on IBM Cloud. IBM lets us have access to their Tech Zone, which gives us the ability to deploy these demo builds in pretty much any region in the world. I set up a demo running in Hong Kong because, at the time, that was the only one that had spare capacity. However, every time I tried to deploy, it failed at different points. I had to delete pods and allow them to recreate themselves again.
A timing issue?
What seemed to be happening is the Operator tries to lay everything down. It will lay the database down, configure the necessary database tables, put the LDAP down and then create the users inside of the LDAP. At the same time, it is checking to see that the previous step has been completed.
I believe, that if a step doesn’t complete in a timely fashion, the next step starts before the previous step has completed its full configuration. When it catches up, the next step has already gone past where it needed to be to get information from the previous step.
I didn’t see any major issues with it breaking during deployment. It just got stuck. Sometimes DB2 hadn’t started properly. Sometimes users hadn’t been configured properly or the configuration inside of OpenShift. Mostly, I found that by deleting a pod – once I worked out which pod is causing the issue – it can restart from scratch and it seemed to catch up with itself and progress through correctly to allow the rest of the deployment to happen.
It was very frustrating and time-consuming finding out what had happened but we’ve got pretty good at spotting it now. There are thousands of lines of logs, and to identify what’s going wrong, we have to search from the start of the deployment and look for errors. Then, we can see what pods need to be restarted or deleted.
Config Maps
Once I had the demo system up and running, it created a list, a config map, which is basically a set of links to the different applications – Navigator, the Content Platform Engine, Business Automation Studio. It set up the default username and password to access all the systems and from there, I could start configuring it as if it’s a fully deployed Cloud Pak.
Demo builds are not built for production or for testing. You don’t have any control over the number of pods, the amount of memory assigned to each pod or the amount of CPU that they’re limited to. Basically, you tell it what components you want, and it goes away and deploys a default set. Someone within IBM has made those decisions, set up all of the scripts to do it, and all of the configs to be able to create everything that’s needed.
From days to minutes
Although it is resource-heavy, there are a lot of applications that are deployed as part of the full Cloud Pak for Automation demo kit. What the Operators are trying to do is take the technical knowledge required to deploy and automatically do all of that installation and configuration for you. It really does mean a demo can be built in hours, not days.
Of course, it really helps if you’re not on a slow network, like me at home. If you are limited to standard broadband speeds, I have found that it is possible to speed things up by creating local copies of the IBM repository of containers so that you only have to download them once. I stored them in a docker repository, Nexus, and configured the Operator to use that rather than going out to the IBM Cloud each time. It’s possible to do that for enterprise deployments as well. This can speed things up from about 2 hours to 30-45 minutes. If you just want to deploy a simple Content build, that might only take 20 minutes. It’s really neat!
Cloud Pak for Business Automation Enterprise deployment
So, on with an Enterprise deployment. You have a lot more control over what to deploy with the Enterprise. Furthermore, I’ve had no problems with timing and getting stuck during the build. Each time I’ve done an enterprise build, it has run through successfully and started up without any issues.
A Simple Content build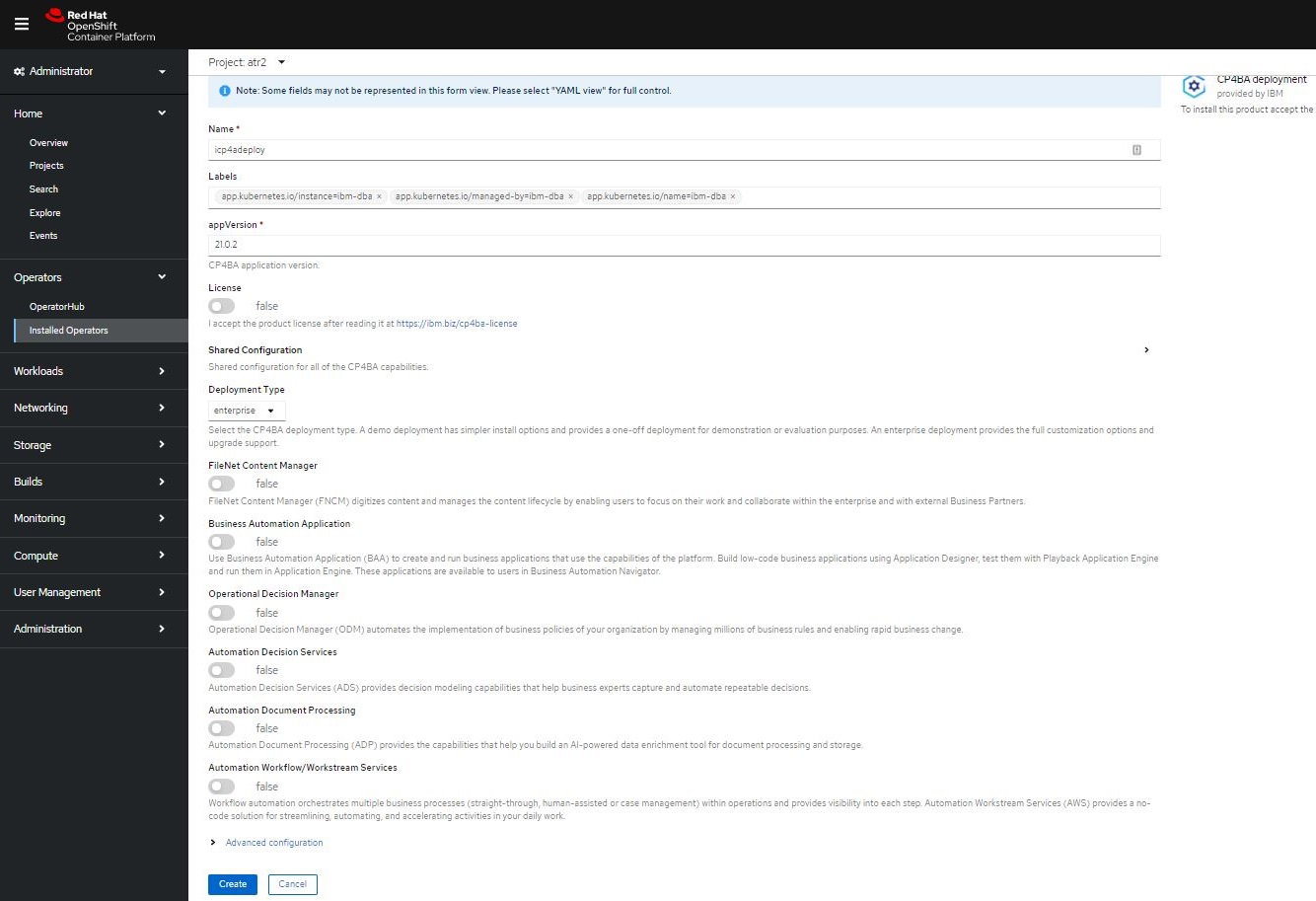
Content builds need a database with four schemas, a directory server – OpenLDAP or Microsoft Active Directory and again you’ve got a choice of either using a GUI or using YAML configuration files. In fact, once you’ve got the first configuration file done, you can actually just use that again and again to deploy on different environments and projects.
Defining the environment
To define the first environment, I chose which components to put down. As I was only building a small development environment, I only wanted one Content Platform Engine and one Navigator pod running. Having control over what resources are being used also has the benefit of being able to keep within customer licensing limits. (Just be aware that IBM will not support a demo build as a production environment).
I needed a database and a directory service to control the users and groups. Beyond that, if you start to look at Business Automation Insights, you need a Hadoop server, which is a Big Data database server for keeping logs, audit events etc. so you can do your graph computations. For some of the Workflow and ODM type rules, you need a GIT library. IBM use GITEA as part of the demo build, but you can use similar libraries such as GitHub or GitLab.
So, I put all my pre-reqs down.
Creating the databases
The demo build creates the database schemas for you, whereas for an Enterprise build you need to create them. For my simple Content build, I needed one Navigator, one for the Global Configuration Data (GCD) and one for an Object Store. If you’re going to be using any sort of Open Identity provider, you need one for UMS. The minimum you can get away with for just Content is three database schemas.
Setting up your users
I set up the users in the same way as if I were running the setup.exe on a native operating system with an admin and a standard type user group. I got the database and the Active Directory ready and put in the configuration to tell it where to locate the databases, the users, passwords and the connections to each of the different servers. Again, you can tell the Operator this either using the GUI or the configuration YAML.
And repeat
Once I’d got one database working, I could create another set of databases with the same schema and just use that again. When it deploys, it gives you a whole set of new URLs to access the system. They can be completely separate within a single Open Shift environment.
Deployment choices
You have greater control over what to deploy with the Enterprise. For example, at times, I have used PostgreSQL rather than DB2 for the database. We’ve used different GIT libraries. We use an Open Identity provider called KeyCloak. For the docker registry, we’ve used Nexus and Open LDAP for the user and group directories.
A customer of ours uses an external Oracle database. They also use their existing Microsoft Active Directory. Starting with the base Enterprise Config we had tested successfully on our office server, we made changes to point to the Oracle Database and the Microsoft Active Directory in the YAML. We deployed the Operator and let it do its work deploying the pods and creating the routes which allow us to give the URLs to access the system to the relevant users defined in the Active Directory.
Next time
Next time, in Clive’s Journey to the Cloud, find out if his Cloud Pak for Business Automation Enterprise build was successful and how to implement additional capability…